Zusammen mit querifai.ai haben wir von Glanos die Leistungsfähigkeit bekannter OCR-Lösungen aus der Cloud unter die Lupe genommen.
Textgenerierung mit ChatGPT und automatische Bilderstellung mit StableDiffusion haben einen regelrechten Hype um künstliche Intelligenz (KI) ausgelöst und nehmen medial einen großen Raum ein. Währenddessen ist auch die Adaption von klassischen KI-Anwendungen in Unternehmen stärker in den Fokus gerückt.
In diesem Artikel werfen wir einen Blick auf das Thema Texterkennung (engl. Optical Character Recognition, im Folgenden OCR). Mit Hilfe von OCR lassen sich gedruckte oder handgeschriebene Texte maschinell verarbeiten.
Wofür wird OCR eingesetzt?
OCR-Systeme werden in unterschiedlichen Anwendungsfällen eingesetzt, unter anderem zur:
- Digitalen Archivierung von Dokumenten: Gedruckte Dokumente können in digitale Textdateien umgewandelt werden und damit durchsuchbar gemacht werden
- Datenerfassung: Extraktion von Informationen aus gedruckten Formularen oder Rechnungen
- Downstream Tasks: Durch die Umwandlung in Text werden verschiedenste KI-Anwendungen wie Zusammenfassungen, Übersetzungen oder Question-Answering ermöglicht
- Mobile Anwendungen für Verbraucher wie das Abfotografieren von Rechnungen im Onlinebanking oder das Auswerten und Verträgen
- Medizin oder andere Bereiche: Handschriftenerkennung z.B. Rezept
Eine Automatisierung spart Zeit und Ressourcen. Dank KI-basierter Verfahren ist die Qualität besser und verlässlicher als bei Bild-zu-Text-Transkriptionen von menschlicher Hand. Darüber hinaus verbessert sich die Qualität fortlaufend mit dem iterativen Anwachsen der analysierten Datenmenge.
Welche Rolle spielt OCR für Glanos?
Glanos anonymization.ai verwendet OCR, um eingescannte oder abfotografierte Dokumente mithilfe von Natural Language Processing zu “lesen”, also in Text zu verwandeln und anschließend zu anonymisieren. Die KI kann sensible Daten schwärzen oder durch sinnerhaltende Platzhalter wie Name1, Name2, Firma1, Land4, usw. ersetzen, wodurch die Lesbarkeit erhalten bleibt. Diese reichen von Telefonnummern und Adressen über Geldwerte bis hin zu Bildern.
Für unsere Anonymisierungssoftware ist OCR also ein wichtiger Schritt, um Entitäten richtig zu erkennen und so sinnerhaltend ersetzen zu können. Generell hängt an der Qualität der OCR immer auch die Erfolgschancen weiterer Automatisierungsschritte wie Metadaten-Anreicherung, Zuordnung zu Geschäftsvorgängen oder Robot Process Automation (RPA).
Was sind die Herausforderungen?
Die Qualität und Genauigkeit der OCR-Erkennung hängen von verschiedenen Faktoren ab, einschließlich der Qualität des Eingabedokuments, der verwendeten OCR-Software und -hardware sowie der Sprache des Texts. Fortschritte in der maschinellen Lerntechnologie verbessern die OCR-Genauigkeit kontinuierlich. Typische Herausforderungen sind Fotos oder Scan mit Schatten, Kanten und keiner geraden Ausrichtung, kleine oder kontrastarme Schriften und handschriftliche Zusätze.
Wie funktioniert OCR?
OCR erfordert eine Vorverarbeitung des Dokuments, um die Qualität zu verbessern und den Text besser erkennen zu können. Dazu gehören das De-Skewing (Begradigung von schiefen Scans), die Rauschentfernung (Schatten, Texturen im Hintergrund, usw.) und die Binarisierung (Farbe/Graustufen werden in Schwarz-weiß gewandelt). Anschließend wird die Schrift normalisiert und der Text segmentiert.
Vortrainierte Modelle, die auf Wahrscheinlichkeiten basieren, erkennen die Buchstaben und verbessern sich kontinuierlich durch Lernfähigkeit. Die Ausgabe dieser Modelle wird nachbearbeitet, um bspw. Rechtschreibfehler zu erkennen.
Layoutinformationen, Tabelleninformationen und andere Attribute sind ebenfalls wichtig. Vorannahmen über den Inhalt können aus dem Layout abgeleitet werden, so sind bspw. Adressen häufig an derselben Stelle in verschiedenen Dokumenten (typischerweise links oben) und können so schnell als solche erkannt werden.
Erfahrungen aus der Praxis
Bei der Suche nach einer geeigneten OCR-Software gibt es im Wesentlichen zwei Ansätze: Open-Source und Closed-Source. Open-Source-Software ist frei verfügbar, während Closed-Source-Software auf nutzungsbasierter Abrechnung beruht.
Open-Source-OCR-Lösungen
Unternehmen mit einem starken IT-Team, das nach einer anpassbaren OCR-Lösung sucht, können von Open-Source-Modellen wie Tesseract profitieren. Die Vorteile von Open-Source-Lösungen liegen auf der Hand: Sie sind in der Regel frei verfügbar, sprach- und plattformunabhängig und werden oft kontinuierlich weiterentwickelt.
Allerdings können die Anwendungen aufgrund ihrer hohen Komplexität schwierig auf spezifische Anwendungsfälle zugeschnitten werden. Obwohl Tesseract hervorragend zur Extrahierung von Fließtext aus Bilddokumenten geeignet ist, bietet es kaum Unterstützung für komplexere Layouts.
Selbstverständlich gibt es auch Open-Source-Lösungen für komplexere Layouts, wie zum Beispiel OCRopus, das von Google entwickelt wurde, um ihren Online-Buchdienst zu unterstützen. Der Anpassungsaufwand bleibt jedoch je nach Anwendungsfall hoch.
Kommerzielle Lösungen
Kommerzielle OCR-Lösungen, die sich auf ausgewählte Anwendungsfälle spezialisiert haben, sind oft benutzerfreundlicher und bieten bereits optimierte Lösungen über eine Schnittstelle oder eine Webanwendung an.
Der Vorteil bei kommerziellen Lösungen ist, dass man im Gegensatz zu Open-Source-Modellen kein eigenes Hosting und keine Diagnose der Modelle benötigt und sich auf getestete Qualität für die jeweiligen Anwendungsfälle verlassen kann.
Allerdings ist bei der Auswahl eines geeigneten Anbieters eine gründliche Recherche notwendig, da nicht jeder Anbieter jeden Dokumententyp gleich gut beherrscht. Es ist wichtig zu beachten, auf welchen Daten die Modelle trainiert wurden und ob diese zu den eigenen Daten passen.
Verschiedene Anbieter im Vergleich
querifai.ai unterstützt bei der Suche nach dem besten Anbieter für die eigenen Daten. Hierzu lädt man ausgewählte Dokumente in der Web-app hoch und schickt diese per Mausklick an verschiedene KI-Services, z.B. von Google, AWS und Microsoft Azure. Die Ergebnisse der unterschiedlichen Anbieter werden dann in der App untereinander angezeigt.
Wenn der jeweilige KI Service Koordinaten (auf dem gescannten Blatt) für den erkannten Text übermittelt, wird in der Auswertung auch angezeigt, welche Teile des Dokuments ausgewertet wurden. Auf diese Weise kann man direkt erkennen, welcher Anbieter welche Bereiche gut erkannt hat und daher am besten geeignet ist.
Im Folgenden sind ein paar typische Anwendungsfälle illustriert.
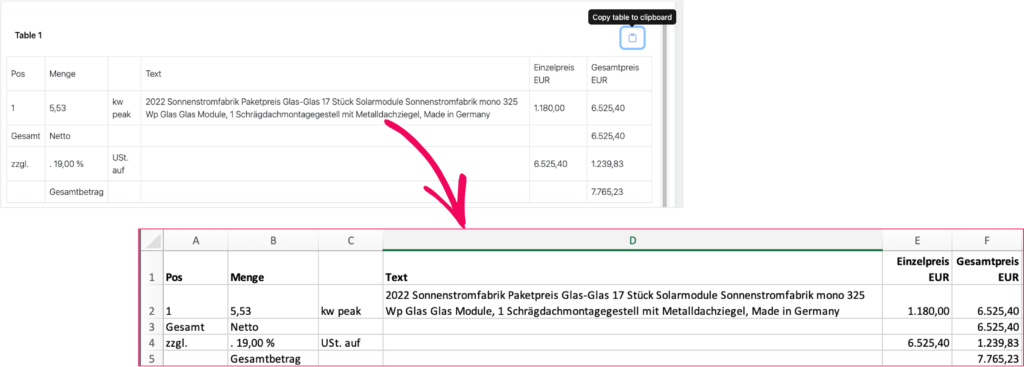
Betrachtet wir zunächst eine einfache Rechnung mit einem einzigen Rechnungsposten und Umsatzsteuerzuschlag:

Mittels Dokumentenanalyse lassen sich von den getesteten Anbietern (AWS, MS Azure, Google) zuverlässig die Rechnungsposten extrahieren. Diese lassen sich auf querifai per Mausklick in ein Tabellenverarbeitungsprogramm extrahieren:
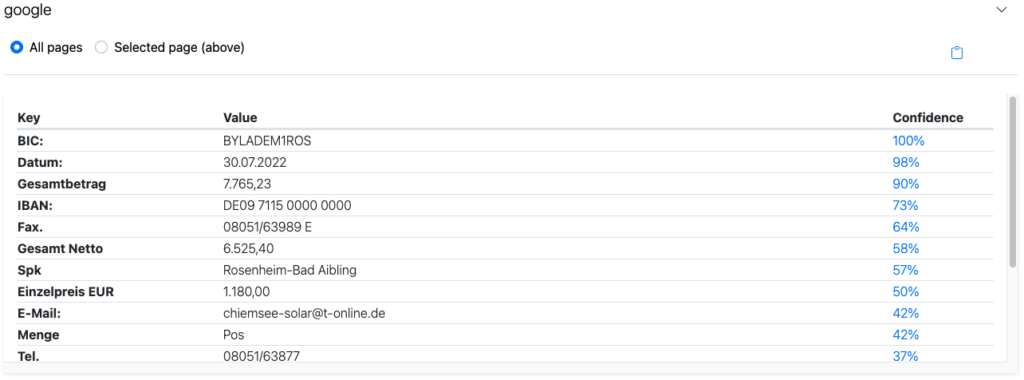
Auch Schlüsselwortpaare werden von den Anbietern gut erkannt, mit kleineren Abweichungen je nach Anbieter.
Qualitative Unterschiede
Grundsätzlich gilt, dass die Input-Bildqualität und die Vorauswahl einer Dokumentenkategorie einen entscheidenden Einfluss auf die Ergebnisse haben. Nehmen wir bspw. das Foto einer Quittung, die auf eine Seite eines Versicherungsvertrages geheftet ist:

Schickt man dieses Bild zur generellen Texterkennung (dokumententyp-unabhängig) an AWS, Google und Azure, wird ein großer Teil des Textes richtig erkannt:

Während alle Anbieter teils unterschiedlich gut die einzelnen Textpassagen erkannt haben, sind die Texte aus der Quittung nur schwer aus dem Text-Output der KI-Services zu extrahieren. Um dies zu vereinfachen, gibt es spezifische Angebote (API Endpunkte). Alle drei Anbieter bieten unter anderem eine spezifische Lösung für Quittungen an.
Allerdings sind diese nicht darauf ausgelegt, Quittungen, die andere Dokumente teils überlagern, zu erkennen, wie man in der Abbildung unten erkennt. Dort sind die Ergebnisse von Google, AWS und Microsoft Azure gegenübergestellt. Keiner der Anbieter konnte die Quittungsinhalte extrahieren. Die weißen Rahmen in der Gegenüberstellung kennzeichnen die Regionen, in denen die einzelnen Algorithmen etwas erkannt haben.

Für einen solchen Anwendungsfall benötigt man daher einen zweistufigen Prozess, in dem zunächst die Kanten der Quittung erkannt werden, diese dann genutzt werden, um die Quittung auszuschneiden, um diese dann im letzten Schritt einem geeigneten Service zuzusenden.
Denn wenn Quittungen isoliert auf einem Scan vorliegen, dann erkennen die Algorithmen auch die Details sehr zuverlässig:
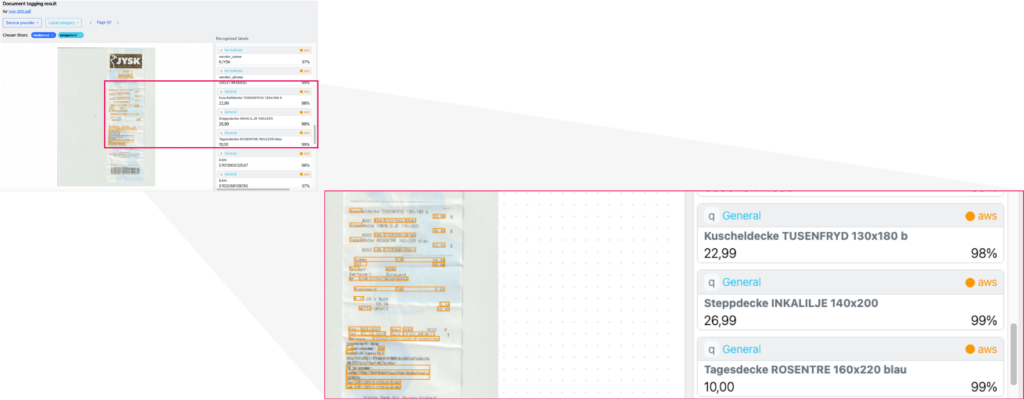
Die Details auf der Quittung, inkl. Produkt und zugehörigen Preisen werden korrekt ausgelesen.
Allerdings lassen sich teils gravierende Qualitätsunterschiede bei den unterschiedlichen Anbietern erkennen, siehe die Abbildung unten. Einer der Anbieter erkennt deutlich weniger Details als die anderen zwei.

Dokumentenanalyse mit KI-Services: Vergleich verschiedener Anbieter für optimale Ergebnisse
Die beschriebenen Beispiele zeigen, dass kommerzielle KI-Services für diverse Dokumententypen gut funktionieren können. Allerdings ist die Qualität für einzelne Dokumente oft sehr unterschiedlich. Deshalb empfiehlt es sich, verschiedene Anbieter und API-Schnittstellen für den jeweiligen Anwendungsfall miteinander zu vergleichen und ggf. sogar zu kombinieren.
Um diesen Vergleich durchzuführen, stellt querifai eine intuitive Webplattform zur Verfügung. Doch nicht nur das: Auch über eine API-Schnittstelle können Kunden ihre Use-Cases direkt in ihrer eigenen Software-Umgebung testen.
Besonders vorteilhaft ist dabei, dass die Schnittstelle bereits ein Standardformat für die verschiedenen APIs bietet. So muss lediglich der „Anbieter-Parameter“ ausgetauscht werden, die Output Formate sind standardisiert.
Neben dem Vergleich von verschiedenen Anbietern ermöglicht querifai auch die Kombination von mehreren Services. So kann beispielsweise ein vier-Augen-Prinzip auf Basis zweier API-Services umgesetzt werden, um sicherzustellen, dass abweichende Ergebnisse gekennzeichnet werden.
Glanos bietet unter anderem Faktendatenbanken und syntaktische Checks für typische Felder wie Adressdaten oder Firmennamen an. So kann beispielsweise die inkorrekt extrahierte IBAN oben im ersten Schritt als fehlerhaft erkannt werden, da mit falscher Länge und Prüfziffer.
Außerdem können z.B. die PLZ- und Ortskombinationen auf Korrektheit geprüft werden oder auch fehlenden Datenpunkte wie Umsatzsteuer-IDs von Firmen bereitgestellt werden, die Glanos von den Homepages extrahiert. Zu den von der OCR bereitgestellten Schlüsselwertpaaren können auch externe Attribute zugespielt werden, wie die Mitarbeiterzahl zu Firmen oder die Größe von Städten.
Zusammenfassung
Optical Character Recognition (OCR) ist eine Technologie, die es Computern ermöglicht, Text aus Bildern oder gedruckten Dokumenten zu erkennen und in digitale Textdateien umzuwandeln. Es gibt verschiedene OCR-Services auf dem Markt, die sich jedoch in ihren Fähigkeiten und Stärken unterscheiden. Um den besten OCR-Service für die eigenen Dokumente auszuwählen, ist es wichtig, die jeweiligen Anforderungen und Dokumententypen zu berücksichtigen.
Die Web-App von querifai hilft Nutzern dabei, den besten OCR-Service für ihre spezifischen Dokumente auszuwählen. Die App vergleicht die Fähigkeiten der verschiedenen OCR-Services auf dem Markt anhand konkreter Beispieldokumente des Nutzers. Auf diese Weise können Nutzer sicherstellen, dass sie den besten Service für ihre Anforderungen auswählen.
Glanos unterstützt Nutzer bei der Validierung der OCR-Ergebnisse sowie der Anonymisierung von Dokumenten. Das Unternehmen bietet eine Reihe von Tools und Services an, die dazu beitragen, die Qualität und Genauigkeit der OCR-Ergebnisse zu verbessern. Darüber hinaus bietet das Unternehmen auch Lösungen für die Anonymisierung von Dokumenten an, um die Privatsphäre und Sicherheit der Nutzer zu gewährleisten.
Zusammenfassend lässt sich sagen, dass die Auswahl des richtigen OCR-Services von entscheidender Bedeutung ist, um die bestmöglichen Ergebnisse zu erzielen. Die querifai Web-App und Unternehmen wie Glanos können Nutzern dabei helfen, den besten Service für ihre Anforderungen auszuwählen und die Qualität und Sicherheit ihrer OCR-Ergebnisse zu verbessern.